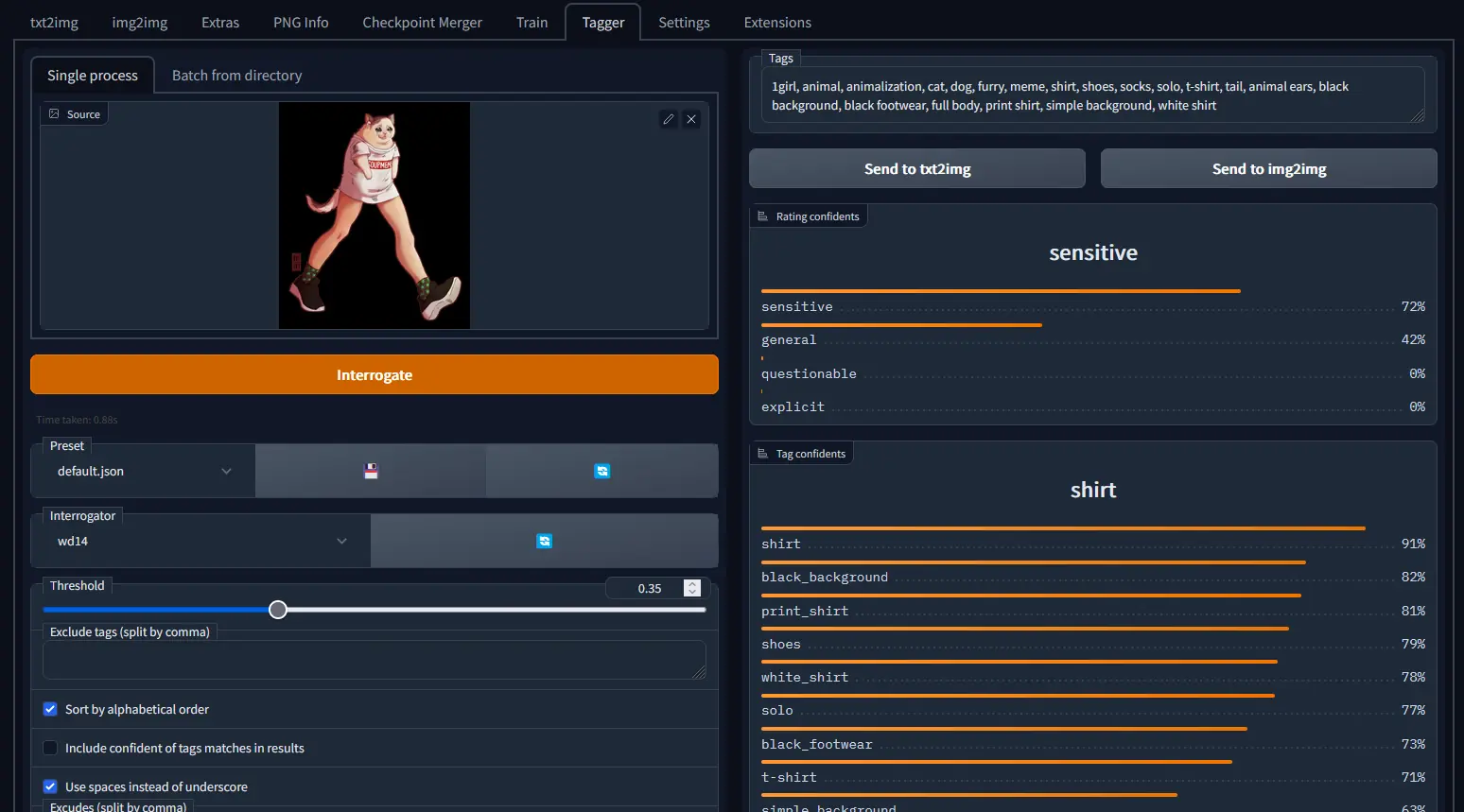
Die automatische Verschlagwortung, Beschriftung oder Beschreibung von Bildern ist eine entscheidende Aufgabe in vielen Anwendungen, insbesondere bei der Vorbereitung von Datensätzen für das maschinelle Lernen. Hier kommen Bild-zu-Text-Modelle zum Einsatz. Zu den führenden Bild-zu-Text-Modellen gehören CLIP, BLIP und WD 1.4 (auch bekannt als WD14 oder Waifu Diffusion 1.4 Tagger).
CLIP: Ein revolutionärer Sprung
OpenAIs Contrastive Language-Image Pretraining (CLIP)-Modell wurde weithin für seinen revolutionären Ansatz zur Interpretation und Generierung von Bildbeschreibungen anerkannt. CLIP nutzt eine große Menge an Internet-Texten und Bilddaten, um eine Vielzahl visueller Konzepte zu erlernen und so beschreibende Sätze für Bilder zu erzeugen.
Allerdings können CLIPs beschreibende Sätze laut Nutzermeinungen manchmal redundant oder übermäßig ausführlich sein. Häufige Kritikpunkte sind die Neigung des Modells, ähnliche Beschreibungen für dasselbe Objekt zu wiederholen oder bestimmte Attribute wie die Farbe eines Objekts überzubetonen.
BLIP: Einfachheit trifft Funktionalität
Das BLIP-Modell bietet, obwohl seine Beschreibungen im Vergleich zu CLIP weniger detailliert sind, einen einfacheren und direkteren Ansatz für die Bild-zu-Text-Verarbeitung. Wie ein Tester bemerkte, ist BLIP „cool und so, aber ziemlich einfach.“ Die Einfachheit dieses Modells kann ein Vorteil für Anwendungen sein, die einfache, weniger ausführliche Tags oder Beschreibungen erfordern.
Dennoch fanden einige Nutzer, dass BLIPs Ausgabe oft die Tiefe und Granularität fehlt, die Modelle wie WD14 bieten. Obwohl es zufriedenstellende Ergebnisse liefern kann, ist BLIP möglicherweise nicht die beste Wahl für Anwendungen, die detaillierte, komplexe Tags erfordern.
Ich habe festgestellt, dass WD14, obwohl es auf Anime ausgerichtet ist, auch gut für tatsächliche Fotos von Menschen funktioniert. Ich kombiniere es normalerweise mit BLIP und meistens nimmt es viel mehr Details auf als BLIP.Toni Corvera bei YouTube Kommentare
Blip ist cool und so, aber ziemlich einfach.
Die WD 1.4 (WD14) Tagging ist viel besser – mehr Details, saftigere Tags.OrphBean bei GitHub
WD 1.4 (aka WD14): Präzision bis ins Detail
Das WD 1.4-Modell (auch bekannt als WD14 oder Waifu Diffusion 1.4 Tagger), ursprünglich für Anime-Bilder entwickelt, hat eine überraschende Vielseitigkeit bewiesen und funktioniert auch gut mit Fotos. Nutzer haben seine erweiterten Konfigurationsoptionen und Batch-Verarbeitungsfunktionen gelobt, die es zu einem robusten Werkzeug für die Bild-zu-Text-Übersetzung machen.
Das Besondere an WD14 ist seine Fähigkeit, detaillierte, „saftigere“ Tags zu generieren und damit im Vergleich zu seinen Pendants ausführlichere Bildbeschreibungen zu liefern. Während dieses Modell weniger wahrscheinlich irreführende Tags produziert, könnte der Fokus auf Anime eine Einschränkung für bestimmte Bildarten sein.
Ist der WD14-Tagger besser als der eingebaute BLIP oder deepdanbooru in Automatic1111?
Die Erweiterung bietet bessere Konfigurations- und Batch-Verarbeitungsoptionen, und ich habe festgestellt, dass sie weniger wahrscheinlich völlig irreführende Tags produziert als deepdanbooru.
CLIP/BLIP ist anders, da diese beschreibende Sätze anstelle von Tag-Listen erstellen, aber Letzteres entspricht normalerweise mehr meinen Bedürfnissen. Und der eingebaute CLIP-Interrogator neigt dazu, Dinge wie „ein Bild von (Beschreibung) und ein Bild von (leichte andere Beschreibung desselben Dings)“ oder „(größtenteils vollständige Beschreibung) und rosa Haare und rosa Haare und rosa Haare und (viele Wiederholungen)“ rauszuhauen.
Trotz der Ausrichtung auf Anime funktioniert der WD14-Tagger ziemlich gut bei Fotos.MorganTheDual bei Reddit
Fazit
Die Wahl zwischen CLIP, BLIP und WD 1.4 hängt weitgehend von den konkreten Anforderungen eines Projekts ab. Wenn Präzision und Detailtiefe von entscheidender Bedeutung sind, bietet WD 1.4 eine überzeugende Option mit seinen erweiterten Konfigurationsmöglichkeiten und detaillierten Tagging-Funktionen. Für einfachere Anwendungen könnte BLIPs geradliniger Ansatz besser geeignet sein. CLIP bietet dabei eine Balance zwischen Detailtiefe und Einfachheit, wenn auch mit einer Tendenz zur Wortreichheit.
Mit der weiteren Entwicklung und Verbesserung dieser Modelle bergen sie ein vielversprechendes Potenzial für ein breites Spektrum von Anwendungen, von der Content-Erstellung bis zur Datenanalyse. Trotz ihrer Unterschiede sind CLIP, BLIP und WD 1.4 ein Beleg für die rasanten Fortschritte in der Bild-zu-Text-Technologie, wobei jedes mit einzigartigen Stärken zu diesem spannenden Bereich beiträgt.