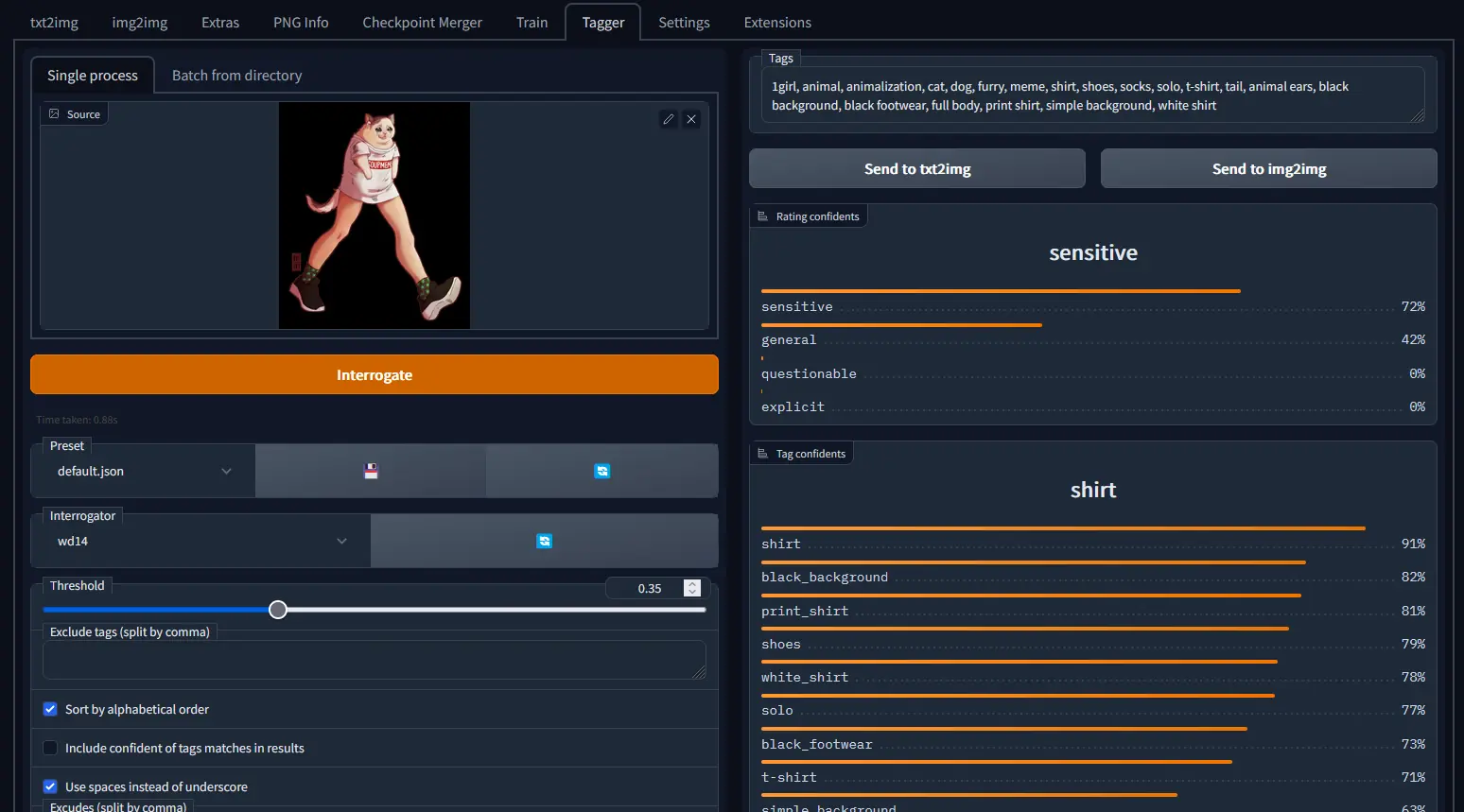
Автоматическая разметка/тегирование изображений является крайне важной задачей во многих приложениях, особенно при подготовке наборов данных для машинного обучения. Для этих целей используются модели Image-to-Text. Среди лидирующих моделей такого типа — CLIP, BLIP и WD 1.4 (также известная как WD14 или Waifu Diffusion 1.4 Tagger).
CLIP: революционный прорыв
Модель Contrastive Language–Image Pretraining (CLIP) от OpenAI получила широкое признание за её революционный подход к генерации описаний изображений. CLIP использует огромное количество интернет-текстов и изображений, чтобы изучить множество визуальных концепций и затем генерировать описательные предложения для изображений.
Однако, по отзывам пользователей, описательные предложения от CLIP иногда могут быть избыточными или чрезмерно многословными. Распространенная критика касается склонности модели повторять похожие описания для одного и того же объекта или чрезмерно акцентировать внимание на определенных атрибутах, таких как цвет объекта.
BLIP: простота и функциональность
Модель BLIP, хоть и менее детализированная в своих описаниях по сравнению с CLIP, предлагает более простой и прямолинейный подход к обработке изображений в текст. Как отметил один из рецензентов, BLIP «крутая, но довольно простая». Эта простота модели может быть преимуществом для приложений, которым требуются прямолинейные, менее развернутые теги или описания.
Тем не менее, некоторые пользователи считают, что выходные данные BLIP зачастую не обладают глубиной и детализацией, обеспечиваемыми моделями вроде WD14. Хотя BLIP может генерировать удовлетворительные результаты, она может быть не лучшим выбором для приложений, требующих подробных, комплексных тегов.
Я обнаружил, что WD14, несмотря на ориентацию на аниме, отлично работает и с реальными фотографиями людей. Я обычно комбинирую ее с BLIP, и в большинстве случаев она выявляет гораздо больше деталей, чем BLIP.
Тони Корвер в комментариях на YouTube
BLIP конечно крутая, но довольно простая.
Тегирование с WD 1.4 (WD14) гораздо лучше — больше деталей, сочные теги.
OrphBean на GitHub
WD 1.4 (также известная как WD14)
Модель WD 1.4 (также известная как WD14 или Waifu Diffusion 1.4 Tagger), изначально предназначенная для аниме-изображений, продемонстрировала удивительную универсальность, хорошо работая даже с фотографиями. Пользователи высоко оценили ее расширенные настройки и возможности пакетной обработки, которые делают эту модель мощным инструментом для перевода изображений в текст.
Отличительной особенностью WD14 является ее способность генерировать подробные, «сочные» теги, обеспечивая более глубокие описания изображений по сравнению с другими моделями. Хотя эта модель менее склонна к появлению ложных тегов, ее ориентация на аниме может быть ограничением для некоторых типов изображений.
В: Лучше ли теггер WD14, чем встроенные в Automatic1111 BLIP или deepdanbooru?
О: Расширение дает лучшие опции для настройки и пакетной обработки, и я обнаружил, что он реже генерирует совершенно ложные теги, чем deepdanbooru.
CLIP/BLIP отличаются тем, что генерируют описательные предложения, а не списки тегов, но последние обычно больше соответствуют моим потребностям. А встроенный допросчик CLIP склонен выдавать вещи вроде «изображение (описание) и изображение (немного другое описание того же самого)» или «(в основном полное описание) и розовые волосы и розовые волосы и розовые волосы и (повторять много раз)»
Несмотря на ориентацию на аниме, теггер WD14 довольно хорошо работает с фотографиями.
MorganTheDual на Reddit
Заключение
Выбор между CLIP, BLIP и WD 1.4 во многом зависит от конкретных потребностей проекта. Если важны точность и детализация, WD 1.4 предлагает привлекательный вариант со своими расширенными настройками и подробным тегированием. Для более простых приложений может быть более подходящим прямолинейный подход BLIP. А CLIP обеспечивает баланс между детализацией и простотой, пусть и со склонностью к многословности.
По мере дальнейшего развития и совершенствования эти модели обладают многообещающим потенциалом для широкого спектра приложений, от создания контента до анализа данных. Несмотря на различия, CLIP, BLIP и WD 1.4 демонстрируют стремительный прогресс в технологиях обработки изображений в текст, каждая внося свои уникальные сильные стороны в это захватывающее поле.