
Что такое Mamba? Mamba — это многообещающая архитектура LLM, предлагающая альтернативу архитектуре Transformer. Её сильные стороны — эффективность памяти, масштабируемость и способность работать с очень длинными последовательностями. Mamba основана на моделях пространства состояний (State Space…
Метка: AI
Новейшие достижения в области архитектур ИИ: Трансформеры, Mamba, I-JEPA
Введение В быстро развивающемся мире искусственного интеллекта стремление к созданию более мощных и универсальных архитектур стало движущей силой некоторых из наиболее впечатляющих прорывов последних лет. От революционных моделей Трансформеров, преобразивших обработку естественного языка, до инновационных…
Stable Diffusion 3: прорыв в области генерации изображений искусственным интеллектом
Stability AI выпустила свою новейшую модель искусственного интеллекта для преобразования текста в изображение, Stable Diffusion 3, что знаменует собой значительный прогресс в быстро развивающейся области генеративного ИИ. Эта новая модель отличается впечатляющими улучшениями в качестве…
Лучшие инструменты ChatGPT для многократного повышения вашей продуктивности

Эти потрясающие инструменты ChatGPT увеличат вашу продуктивность во много раз! Исправитель грамматики в ChatGPT Исправитель грамматики работает очень просто: вы отправляете любой текст, и он возвращает вам тот же текст, но с исправленной грамматикой. Это…
Cerebras Systems заключила сделку на создание крупнейшего в мире суперкомпьютера для ИИ

Санта-Клара, Калифорния — 20 июля 2023 г. — Компания Cerebras Systems, ведущий поставщик решений для искусственного интеллекта (ИИ) на основе технологии производства чипов, занимающих всю кремниевую пластину, объявила о крупной сделке с G42, технологическим конгломератом…
AI модели для разметки изображений (Image-to-Text): CLIP, BLIP, и WD 1.4 (aka WD14)
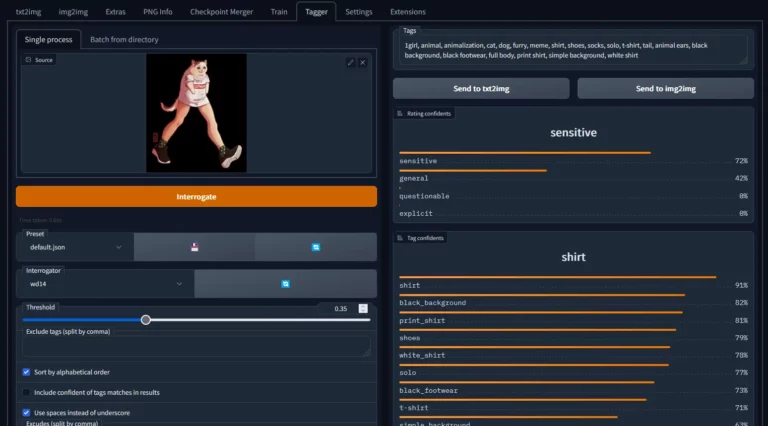
Автоматическая разметка/тегирование изображений является крайне важной задачей во многих приложениях, особенно при подготовке наборов данных для машинного обучения. Для этих целей используются модели Image-to-Text. Среди лидирующих моделей такого типа — CLIP, BLIP и WD 1.4…
Увеличение изображений в Automatic1111: Tiled VAE и Multidiffusion Upscaler

Создание высококачественных изображений в Automatic1111 стало еще проще благодаря Tiled Variational Autoencoder (VAE) и Multidiffusion Upscaler. Эти мощные инструменты позволяют пользователям генерировать впечатляющие 4K+ изображения без видимых швов или сложных шагов. Обзор Tiled VAE Tiled…