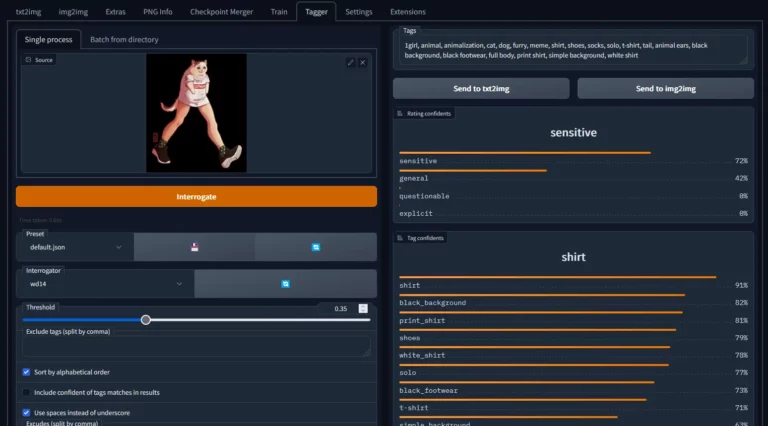
Die automatische Verschlagwortung, Beschriftung oder Beschreibung von Bildern ist eine entscheidende Aufgabe in vielen Anwendungen, insbesondere bei der Vorbereitung von Datensätzen für das maschinelle Lernen. Hier kommen Bild-zu-Text-Modelle zum Einsatz. Zu den führenden Bild-zu-Text-Modellen gehören…