The world of artificial intelligence is constantly evolving, and a recent breakthrough in AI research has taken things to the next level. A new paper introduces “Reflection,” an autonomous agent with dynamic memory and self-reflection capabilities, allowing AI models to learn from their own mistakes and improve over time. This development gives AI models human-like reasoning abilities and promises a significant boost in performance.
What is Reflection and Why is it Significant?
One of the biggest weaknesses of current AI models is their inability to learn from their mistakes. Reflection addresses this by giving an agent dynamic memory and self-reflection capabilities, enhancing their existing reasoning, trace, and task-specific action choice abilities. In simple terms, the model can now memorize the actions it has taken, review those actions, and correct its mistakes.
The great thing about this approach is that it’s not limited to GPT-4 models; it can work with any large language model without the need for fine-tuning. The reflection model simply evaluates the reward function and updates the action that needs to be taken by the original large language model, giving a huge boost in performance.
The Original Reflection Paper
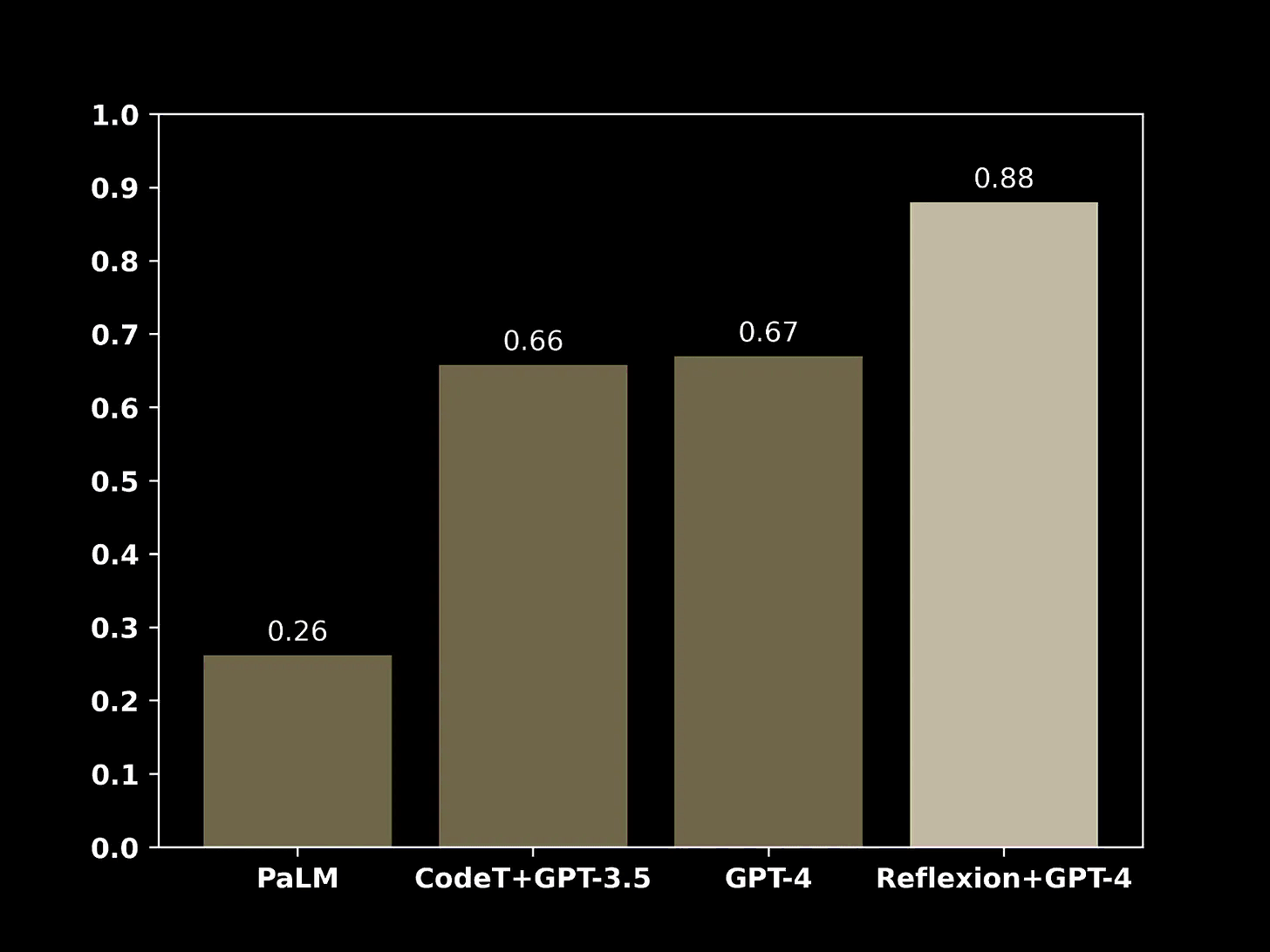
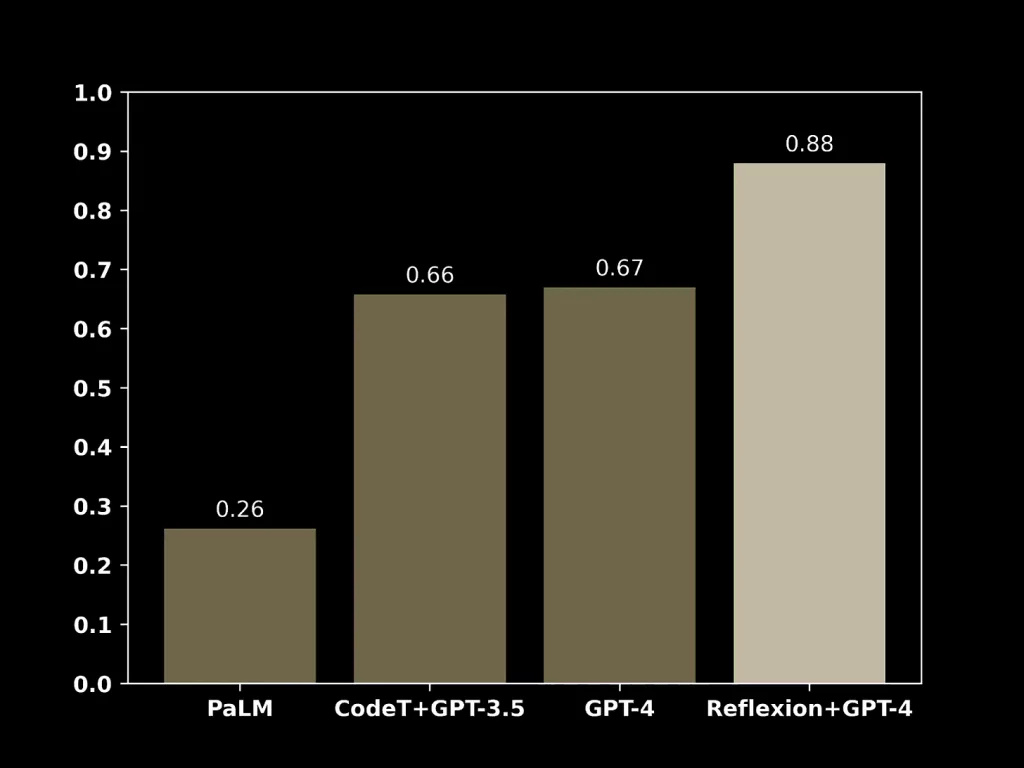
The original reflection paper presents results on two different datasets, showcasing its ability to reason:
- Hotpot QA: A dataset for diverse, explainable multi-hop question answering, requiring the language model to reason through multiple documents.
- ELF World: Aligning text and embodied environments for interactive learning, combining text inputs and outputs with the physical world, allowing the model to interact with the physical world using text prompts.
Adding reflection to these models led to significant performance improvements, without the need for fine-tuning.
Dispelling Misconceptions About the Paper
Many people mistakenly believe that the paper uses GPT-4, but it actually uses GPT-3 and 3.5 (ChatGPT). This distinction is significant because it opens up the possibility of combining reflection with Auto GPT, enabling AI models to modify tasks on the fly, providing true intelligence.
Reflection in Action: An Example
In a Hotpot QA task, the model needed to find the name of an actor best known for a role in a specific show. After an initial unsuccessful attempt, the model used reflection to identify the mistake in its search strategy, correct it, and ultimately find the correct answer. This is exactly how a human would approach a problem, reflecting on their mistakes and adjusting their strategy accordingly.
Limitations and Addressing Situations Without Definitive Ground Truth
One major limitation of the paper is that it requires ground truth to work. However, in many real-world situations, there isn’t a definitive ground truth or single optimal solution. The authors of the paper propose a method that mirrors human problem-solving, creating an internal test suite based on their understanding and then adjusting solutions until they satisfy most of the tests.
By shifting the accuracy bottleneck from correct syntactic and semantic code generation to correct syntactic and semantic test generation, the model can achieve higher accuracy rates.
The Future of AI and Reflection
As AI models with reflection capabilities become more widespread, we can expect to see significant improvements in AI-generated code and other complex tasks. With the ability to iteratively improve their own work, AI models will become more efficient and effective in solving problems and generating solutions.
It’s essential for us as humans to reflect on the developments we’re making in AI and consider the direction we want to take it in. This breakthrough in AI reasoning is just the beginning, and there’s no doubt that more exciting advancements lie ahead.
Video by Prompt Engineering
References:
- Reflexion paper: https://arxiv.org/pdf/2303.11366.pdf
- Reflecting on Reflexion Blogpost: https://nanothoughts.substack.com/p/reflecting-on-reflexion
- HotpotQA paper: https://arxiv.org/pdf/1809.09600.pdf
- Alfworld paper: https://arxiv.org/pdf/2010.03768.pdf
- AutoGPT: https://github.com/Torantulino/Auto-GPT
- HumanEval: https://arxiv.org/pdf/2107.03374.pdf